
Error Budgets Over Deadlines: Why SLOs Are the Release Throttle for AI-Accelerated Delivery
Deadlines are the wrong control variable for software delivery, and AI-accelerated teams prove it weekly. Here is how error budgets and SLOs, borrowed from site reliability engineering, give delivery leaders a reliability-denominated throttle for when to ship and when to stop.

The deadline is the worst control variable in software delivery, and it is the one almost every team still steers by. We pick a date, we burn toward it, and we let the calendar decide when the work is allowed to ship. The problem is that a date has no opinion about whether your last twenty changes made the product better or worse. It cannot see that your error rate doubled on Tuesday. It just sits there, green, while quality quietly erodes underneath it. In two decades of running delivery I have watched more programs get hurt by hitting their date than by missing it.
That was a tolerable mistake when humans wrote all the code, because human throughput was naturally rate limited. It is a dangerous one now. The moment you let AI agents generate and merge code, the cost of producing a change collapses, the volume of changes explodes, and the only thing standing between "fast" and "fast and broken" is a mechanism that actually measures whether the system still works. The calendar is not that mechanism. The error budget is.
Velocity Is Not a Control Variable
Start with the uncomfortable data. Google's 2024 State of DevOps report found that for every 25 percent increase in AI adoption on a team, delivery throughput dropped an estimated 1.5 percent and delivery stability dropped an estimated 7.2 percent. Read that again. Stability got worse, not better, as teams leaned on AI. The same report found that 75.9 percent of respondents now rely on AI for part of their work, so this is not a fringe effect. It is the median team's experience.
The mechanism is not mysterious. AI makes it trivial to write more code, and bigger changesets have always carried more risk. The code analysis firm GitClear looked at 211 million changed lines and found that code churn, the share of lines revised or deleted within two weeks of being written, climbed from 3.1 percent in 2020 to 5.7 percent in 2024. Copy and pasted lines rose from 8.3 percent to 12.3 percent over the same window, while refactored "moved" lines collapsed from 24.1 percent to 9.5 percent. The plain reading: teams are producing more code, duplicating more of it, and reworking it faster after it ships.
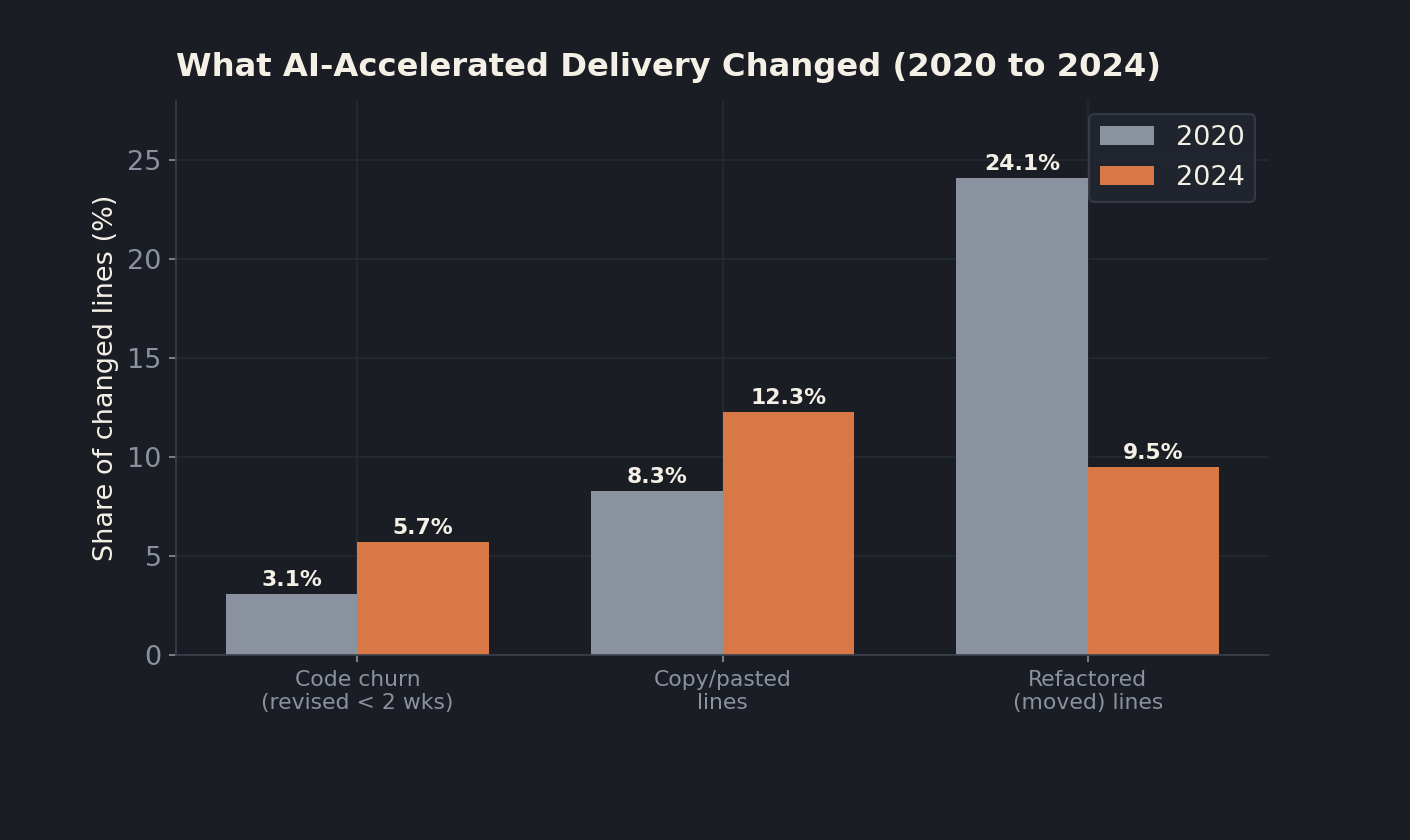
So velocity went up and reliability went down, on the same teams, at the same time. If your only steering instrument is "are we shipping fast enough to hit the date," you are flooring the accelerator with the windshield painted over. I made a related argument about why throughput metrics stop telling the truth in DORA metrics in the agentic era. This post is about the other half of that problem: what to steer by instead.
What an Error Budget Actually Is
The idea comes from site reliability engineering, and it is one of the few ideas from that discipline that transfers cleanly to general delivery leadership. You start with a service level indicator, an SLI, a measurable property of your service that a customer would actually notice: request latency, error rate, availability, successful checkout rate. You then set a service level objective, an SLO, the target for that indicator over a window of time. "99.9 percent of requests succeed in a rolling 28 day window" is an SLO.
Here is the move that changes everything. Your error budget is one minus your SLO. A 99.9 percent availability target gives you a 0.1 percent error budget. If your service handles a million requests in that window, you are allowed to fail a thousand of them. That thousand is not a failure state. It is a budget. It is permission to take risk, denominated in the one currency your customers actually care about.
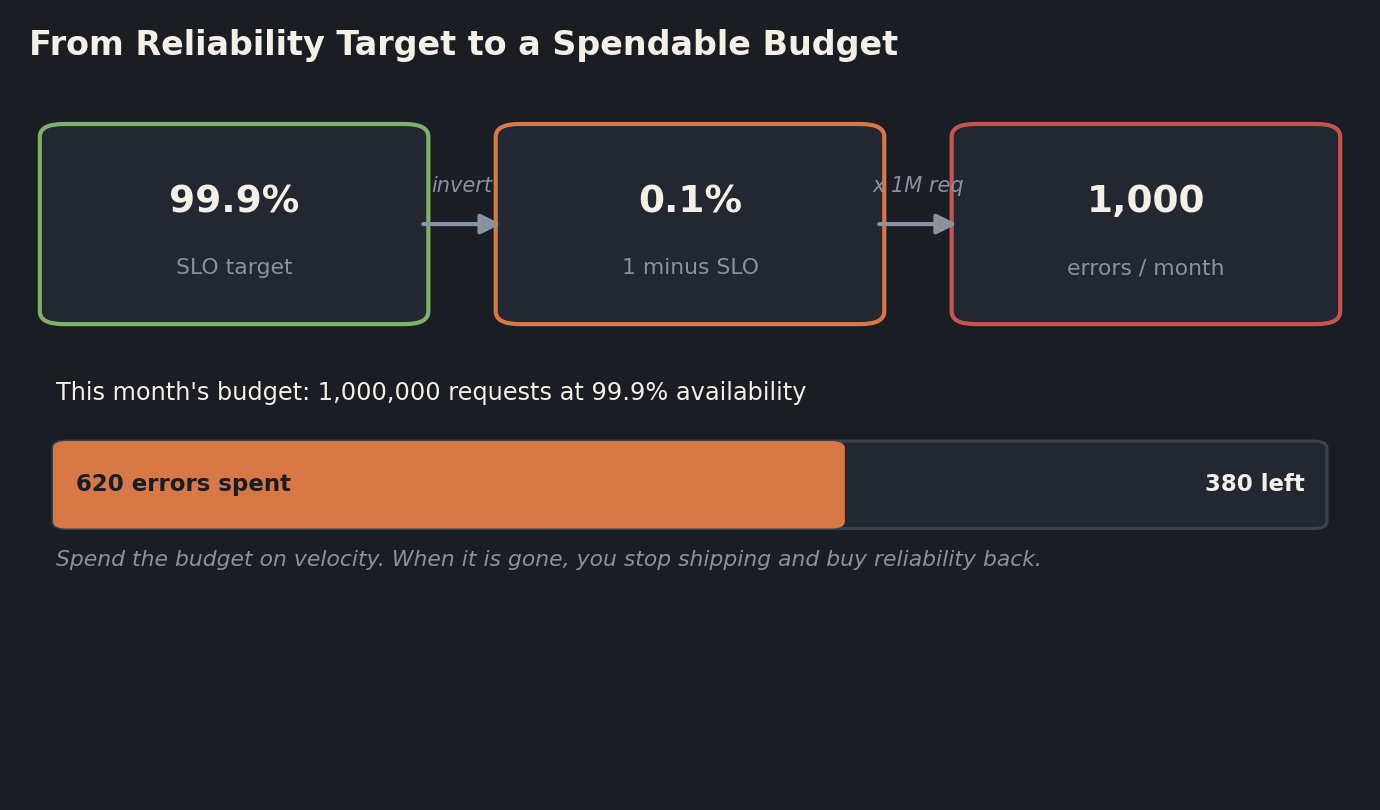
The reframe is subtle and powerful. Reliability stops being an absolute ("nothing can break") and becomes a quantity you spend ("we can afford to break this much"). Every risky release, every aggressive refactor, every agent-authored merge spends some of the budget. As long as there is budget left, you are free to move fast. When the budget is gone, you stop. Google's own SRE practice describes the error budget as the thing that removes the politics from the endless fight between the people who want to ship features and the people who want to keep the system up. Nobody is arguing about feelings anymore. There is a number, and it is either positive or it is not.
The Control Loop: Ship Until the Budget Runs Out
Once reliability is a budget, release governance becomes a control loop instead of a countdown. You measure your SLIs continuously, you compare them to your SLO, and you ask one question on every release decision: is there error budget remaining for this window?
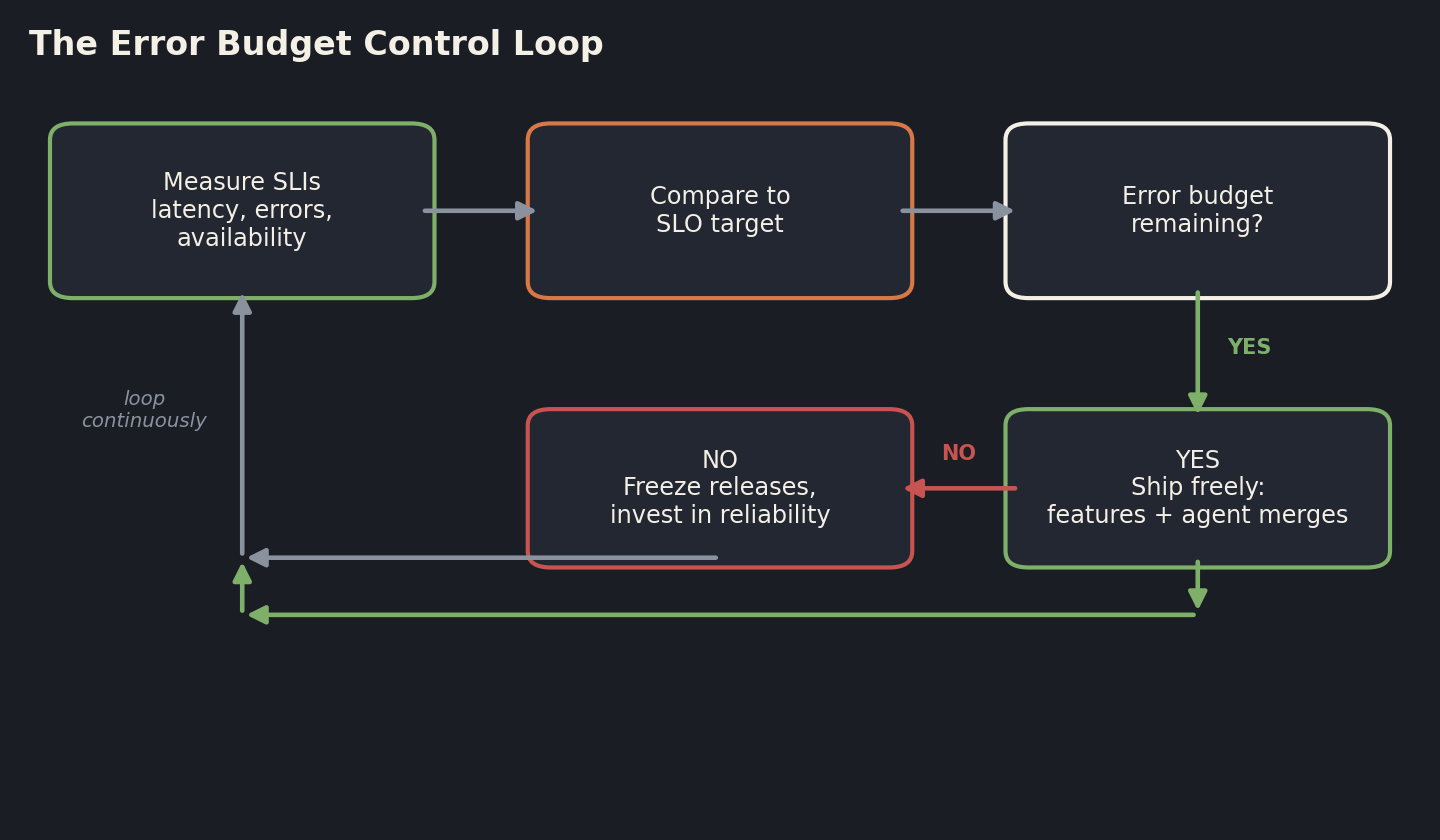
The loop is simple to state and hard to game. If there is budget left, releases flow freely, including the high volume of agent-generated changes that would otherwise terrify you. If the budget is spent, releases freeze, and the team's priority shifts to reliability work until the budget recovers in the next window. That is the entire mechanism. Its power is that the decision is automatic and the criterion is external to the people under deadline pressure.
This is the part most teams get wrong: the freeze is not a punishment and it is not a failure. It is the system working exactly as designed. A spent budget is information. It tells you that you took more risk than your reliability target allows, and now you pay it back. The teams that treat the freeze as an emergency are usually the same teams that treat a red status report as a surprise, a pattern I unpacked in status reports that lie. A well-run error budget never surprises anyone, because everyone watches it burn down in real time.
The chart at the top of this post shows the two trajectories I see most often. Both teams turned on agentic merging. The first had no reliability gate, so every cheap, plausible, agent-authored change spent budget unchecked; the budget was gone by week six and the team spent the rest of the quarter in an involuntary freeze, shipping nothing. The second team ran the same agents under an error budget policy. When their burn rate spiked mid-quarter, an alert fired, they slowed the risky merges, and they finished the quarter with budget to spare and features still shipping. Same tooling, same speed ceiling, completely different outcome. The difference was the throttle.
Watch the burn rate, not just the balance
One refinement worth adding early: track the burn rate, not only the remaining balance. A budget that is 70 percent full looks healthy until you notice it dropped thirty points in three days. Burn-rate alerts (for example, "we are consuming budget fast enough to exhaust it in five days") catch trouble while you still have room to react. The balance tells you where you are. The burn rate tells you where you are going.
Why This Matters More When Agents Ship Your Code
Everything above predates the current AI wave by a decade. So why is it suddenly urgent? Because the error budget is the only release throttle that does not care who wrote the code. A human pull request and an agent pull request spend the budget the same way: by the failures they cause in production. Most of the governance that teams bolt onto AI coding, mandatory human review, longer freeze windows, extra approval gates, tries to slow the author down. That does not scale when the author is a fleet of agents opening fifty pull requests a day, and it punishes good changes alongside bad ones.
An error budget inverts the control. It does not throttle the author; it throttles the blast radius. Agents can merge as fast as they like while the budget is healthy. The instant their changes start degrading the indicators customers feel, the budget burns down and the gate closes on everyone, human and agent alike. You keep the speed without writing a blank check on reliability. This is the production-side complement to the pre-merge discipline I argued for in vibe coding with precision: verification catches what it can before the merge, and the error budget catches what it misses after.
There is a governance dividend too. When 39.2 percent of engineers say they distrust AI-generated code, as they did in the DORA survey, "trust me, the agent is fine" is not a policy. "The agent ships while we have budget and stops when we do not" is a policy, and it is one you can defend in front of a risk committee.
Putting It Into Practice
You do not need a platform team or a full year to start. You need three decisions.
Pick SLIs your customers would actually notice
Resist the urge to measure everything. Two or three indicators per critical user journey is plenty: availability and latency for most services, plus one journey-specific success rate such as checkout completed, payment cleared, or search returned results. If a metric would not make a customer angry when it degrades, it is not an SLI, it is a vanity number.
Set the SLO from business tolerance, not aspiration
This is where most teams fail. They pick 99.99 percent because it sounds responsible, blow the budget in week one, and then ignore it forever. Set the target at the level where the business actually feels pain, and let cost anchor the conversation. ITIC's 2024 survey found that more than 90 percent of mid-sized and large enterprises now lose over 300,000 dollars for a single hour of downtime, and 41 percent put the figure between one and five million dollars an hour. Those numbers tell you what an extra nine of reliability is worth and whether you can afford to spend it. An SLO you will actually enforce at 99.9 percent beats an aspirational 99.99 percent that you quietly abandon.
Write the error budget policy down before you need it
The policy fits on one page. It states the SLO, the measurement window, what happens at 50 percent budget burn (a warning and a review of recent risky changes), and what happens at 100 percent burn (releases freeze, reliability work takes priority, a named owner approves the unfreeze). Wire the trigger into the same release gate you already run. If you keep a release checklist, the budget check becomes one more line on it. The policy matters most in the moment the budget runs out, because that is exactly when the pressure to "just ship this one" is highest. A rule you agreed to in calm is what protects you in the panic.
The Real Shift Is Cultural
The mechanics of error budgets are easy. The hard part is what they ask of leaders. For a generation, delivery leadership has been measured on a single question: are we on schedule? The error budget replaces it with a better one: how much budget do we have left? That second question is harder to answer and far more honest, because it ties the pace of delivery to the lived experience of customers instead of to a date someone committed to in a planning meeting two quarters ago.
This is the same shift, from motion to outcome, that runs through everything I write about modern delivery. Velocity feels like progress. Hitting the date feels like winning. But a customer has never once cared how fast you shipped or whether you made your deadline. They care whether the thing works when they need it. The error budget is the rare governance tool that measures exactly that, and in an era where more of your code is written by something that does not sleep, does not get tired, and does not feel the consequences of a 3 a.m. outage, it may be the only throttle left that still means something.
Stop steering by the calendar. Start steering by the budget.
References
- Beyer, Jones, Petoff, Murphy (eds.). Site Reliability Engineering, Embracing Risk and Service Level Objectives. sre.google
- Google SRE. Implementing SLOs and the Error Budget Policy. sre.google
- DORA. Accelerate State of DevOps Report 2024. dora.dev
- GitClear. AI Copilot Code Quality: 2025 Research. gitclear.com
- ITIC. 2024 Hourly Cost of Downtime Report. itic-corp.com