
FinOps for AI: Why LLM Cost Is an Engineering Problem, Not a Finance One
Per-token prices have collapsed while enterprise AI bills keep climbing. The cost of an AI feature is now decided in architecture and code, not in procurement. Here is how delivery leaders turn LLM cost into a first-class engineering KPI using attribution, budgets, unit economics, and cost gates.

A platform team I worked with last quarter did something that felt like an obvious win. They swapped the model behind their flagship AI feature for one that cost roughly ten times less per token, checked the price of a single request, and told their VP they had cut the feature's running cost by ninety percent. Six weeks later, the monthly bill for that feature had tripled.
Nothing had actually broken. The per-token price really had fallen. But cheaper tokens made the feature cheap enough to use everywhere, so the team wired it into three more workflows, widened the context window to lift quality, and added a second model call to check the first. Lower unit price, many more units, a much bigger bill. This is the trap almost every enterprise is walking into right now, and it has an old name from economics: the Jevons paradox. When a resource gets cheaper to use, people use so much more of it that total spending climbs instead of falling.
The macro numbers say this is not one team's mistake, it is the shape of the whole market. Stanford's 2025 AI Index found that the inference cost for a system performing at the level of GPT-3.5 fell from about twenty dollars per million tokens in late 2022 to seven cents by late 2024, a drop of more than two hundred and eighty times. Across almost the same window, Menlo Ventures measured enterprise spending on generative AI climbing from 2.3 billion dollars in 2023 to 13.8 billion in 2024, then on to 37 billion in 2025. Prices fell through the floor. Spending went to the moon.
That gap between collapsing prices and exploding bills is the entire reason "FinOps for AI" has gone from a niche phrase to the fastest moving topic in technology finance. The FinOps Foundation's State of FinOps 2026 survey, drawn from practitioners responsible for more than eighty three billion dollars of cloud spend, found that ninety eight percent of respondents now manage AI spend, up from sixty three percent a year earlier and just thirty one percent the year before that. Respondents named AI cost management the single most important skill their teams need to build. In two years it went from a rounding error to the headline.
Here is the part most finance organizations have not absorbed yet. You cannot manage this bill from the finance side, because almost nothing that drives it lives in finance. It lives in your codebase.
The Bill Is Written in the Codebase
For fifteen years, cloud FinOps has mostly been about managing resources that someone provisions and someone else pays for: an oversized instance here, an idle database there, a reserved-capacity discount left on the table. The biggest levers were procurement levers. You could trim a cloud bill meaningfully without a single engineer changing a line of code.
AI cost does not work that way. The cost of an AI feature is set, almost entirely, by decisions that engineers and product teams make while they build it. Strip the feature down to its meter and the monthly cost looks like this:
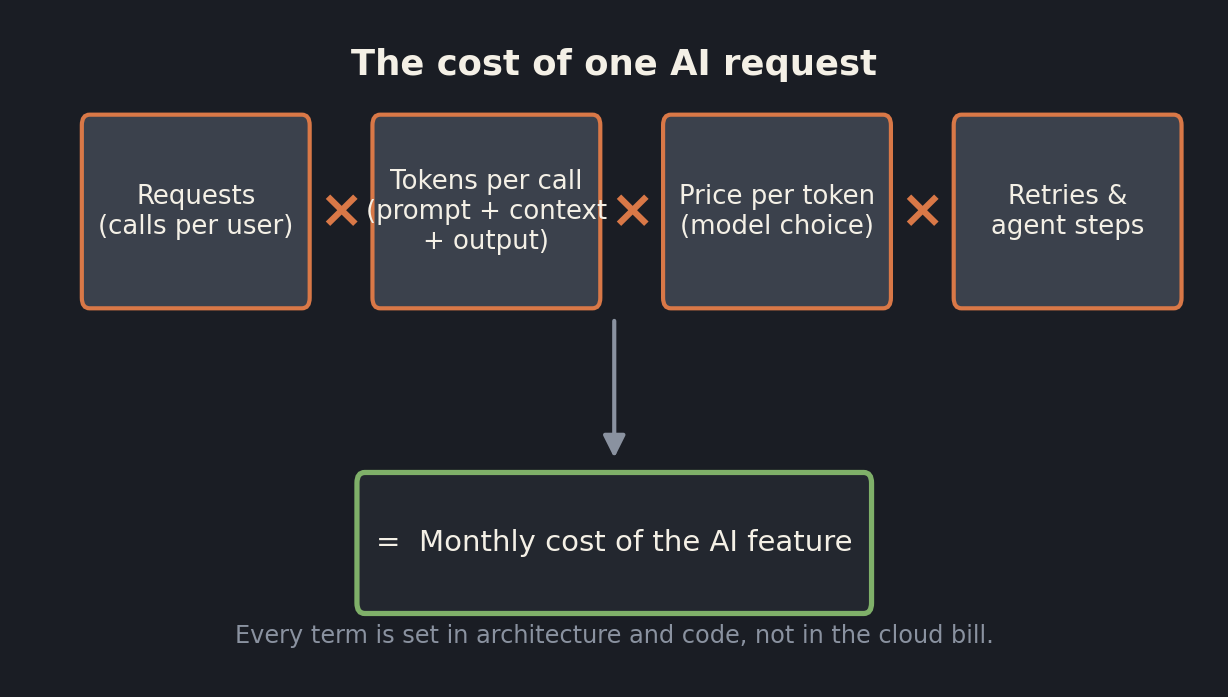
Every term in that product is a design choice. Model selection sets the price per token, and the spread is enormous; a frontier model can cost twenty to fifty times more per token than a small one that would have answered the question just as well. Context size sets the input tokens, and the easy habit of stuffing an entire document, a long history, or a generous pile of retrieved chunks into every prompt is the most common source of silent cost growth. Output length is a setting most teams never tune. And retries and agent steps are the quiet multiplier of the agentic era: an agent that loops eight times to finish a task costs eight times what a single call would, and a guardrail or judge model that checks each response, a quality pattern well worth having, quietly doubles the number of calls behind one user action.
None of those decisions is made by procurement. They are made in pull requests, in prompt templates, in the retrieval configuration, and in the loop conditions of an agent, sprint after sprint. That is the whole argument in one sentence. Rightsizing an instance is an operations task; rightsizing a prompt, a model, and an agent loop is an engineering task, which means the cost lever has moved from the finance team to the delivery team. Treating LLM spend as a line item that finance will optimize later is like asking finance to make your application faster. They can see the number. They cannot move it.
Stop Watching the Bill, Start Watching Unit Cost
Once you accept that cost is an engineering output, the next mistake to avoid is governing the wrong metric. The total bill is the number everyone stares at, and on its own it is close to useless. A bill that doubled this quarter could mean you are scaling a feature customers love, or it could mean you are leaking money on waste. The total cannot tell the two apart.
The number that can is unit cost: cost per request, and better still, cost per resolved task or cost per successful outcome. Pick the unit of value the feature actually delivers, a resolved support ticket, an accepted draft, a completed booking, and divide spend by that unit.
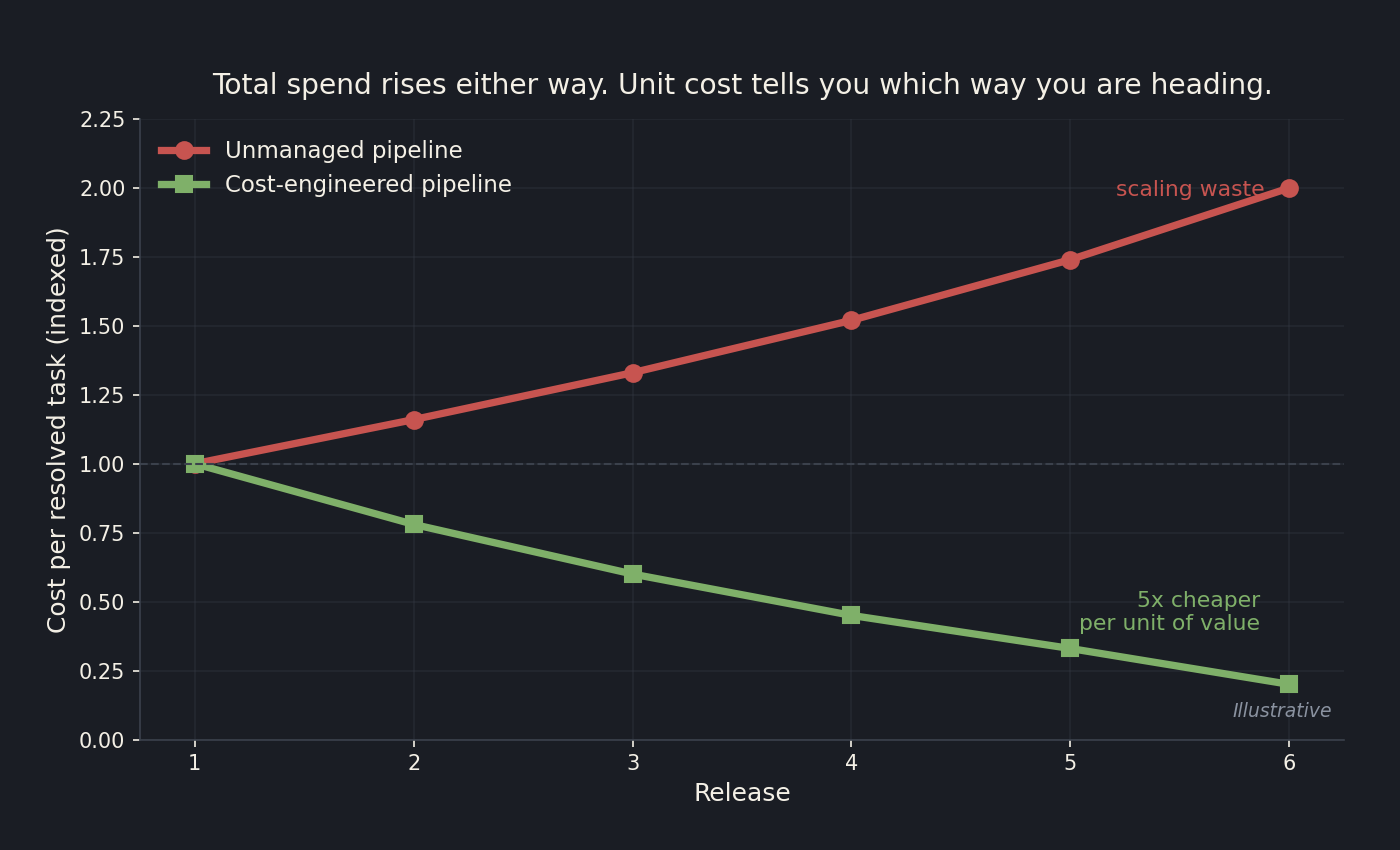
A healthy AI product drives unit cost down over time, even while the total bill rises with adoption. An unhealthy one lets unit cost drift upward, so every new user makes the economics worse. The total looks the same in both cases for a while, which is exactly why it fools people. This is the same point I made in DORA metrics in the agentic era: when the world underneath your dashboard shifts, the comfortable top-line number keeps looking fine long after it stopped meaning what you think it means.
Unit cost also reframes the conversation from cost-cutting to value, which is precisely where the discipline is heading. The State of FinOps 2026 results retitled the whole practice around technology value rather than pure savings, and cost per unit of value is the bridge between an engineering decision and a business one. It is also the metric that keeps a cost program honest, because it refuses to reward you for simply spending less on something nobody uses. If your AI program cannot yet state the cost of one unit of the value it produces, that gap is the same one I wrote about in why your agentic AI strategy will fail without product thinking: you are optimizing activity instead of outcomes.
Make Cost a First-Class KPI, Not a Quarterly Surprise
Knowing that cost is an engineering metric is not the same as controlling it. Control comes from a loop, the same operate-and-improve loop FinOps has always run for cloud, adapted for the things that make AI different.
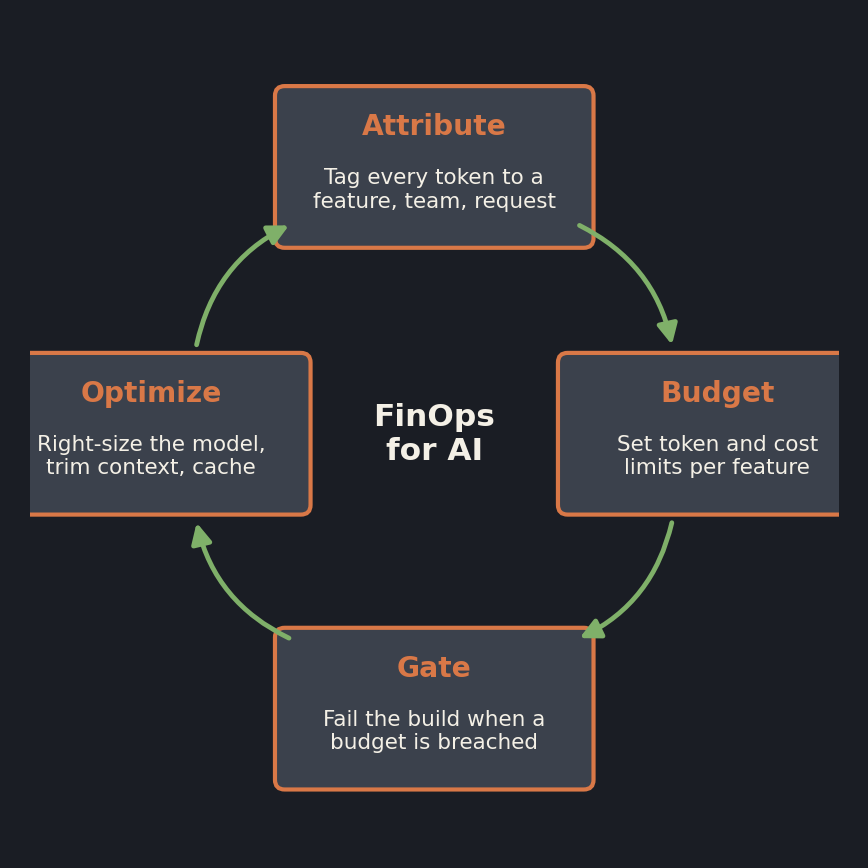
Attribute first, because you cannot manage what you cannot see. Most organizations get one undifferentiated AI invoice and no idea which feature, team, or customer drove it. Fixing that means tagging usage at the source: metadata on every model call, separate keys or projects per feature, and a mapping from spend back to the team that owns it. Until that exists, every other step is guesswork.
Set budgets at design time. A per-feature token budget, or a target cost per request agreed when the feature is specified, turns cost from an afterthought into a requirement, the same way a performance budget caps page weight before anyone ships.
Gate the budget in delivery. You almost certainly already run evals before an AI release; measure cost in that same run and fail the build when a change blows past its per-request budget, exactly as you would fail it for a dropped quality score. A budget that everyone can quietly exceed under deadline pressure is not a budget. The gate is what makes it real.
Then optimize, with the levers that actually move the meter: right-size the model for each task instead of defaulting to the most capable one, trim and cache context, memoize repeated calls, batch where latency allows, and put a hard ceiling on every agent loop. That last point is where cost control and governance become the same problem. When an agent can decide on its own to make more model calls, an unbounded loop is both a reliability risk and a runaway cost, which is the accountability hole I described in the AI agent governance gap. A budget someone signed off on, enforced by a ceiling in code, is how you close it.
What To Do Before Your Next AI Release
You do not need a platform team or a procurement initiative to start. You need to treat the next release as the first one that ships with a price tag.
Put a number on a single request. Take one AI feature and work out, end to end, what one user action costs in tokens and calls today. Most teams have never done this, and the number is usually a surprise.
Define the unit of value and track cost against it. Decide what one successful outcome is for the feature, then watch cost per outcome, not the monthly total.
Set a per-request cost budget and wire it into your eval run. Reuse the quality gate you already have, and add a cost threshold next to the quality threshold.
Tag spend so you can attribute it. Even coarse tagging by feature beats a single bill, and it is usually a day of work rather than a project.
Give every agent loop a hard ceiling. Cap the steps and model calls an agent can make per task, and alert when it hits the cap, so a bad prompt cannot turn into a four figure afternoon.
The Honest Part
Cheaper tokens are not a discount. They are an invitation to spend more, and most organizations are accepting it without noticing. The per-token price will keep falling, and the bill will keep rising, because falling prices are exactly what pull more usage into existence. That is not a problem you solve once; it is a meter you watch continuously.
The teams that come out ahead will treat LLM cost the way mature engineering organizations already treat latency and reliability: as a design constraint owned by the people writing the code, measured per unit of value, and checked before release rather than explained after the invoice lands. FinOps for AI really is just FinOps, as the FinOps Foundation likes to say. The difference is that the controls no longer live in a procurement contract. They live in your architecture, your prompts, and your pipelines. The bill is going to grow either way. The only question worth answering is whether it grows because your product is winning, or because nobody was watching the meter.
References
- Stanford HAI. The 2025 AI Index Report. hai.stanford.edu
- FinOps Foundation. The State of FinOps 2026. data.finops.org
- FinOps Foundation. FinOps for AI. finops.org
- Menlo Ventures. 2024: The State of Generative AI in the Enterprise. menlovc.com