
DORA Metrics in the Agentic Era: Why Deployment Frequency Stops Being a Signal
DORA metrics defined modern software delivery for a decade. With agentic AI shipping code on its own, deployment frequency and lead time can lie to you. Here is the new metric stack engineering leaders actually need.
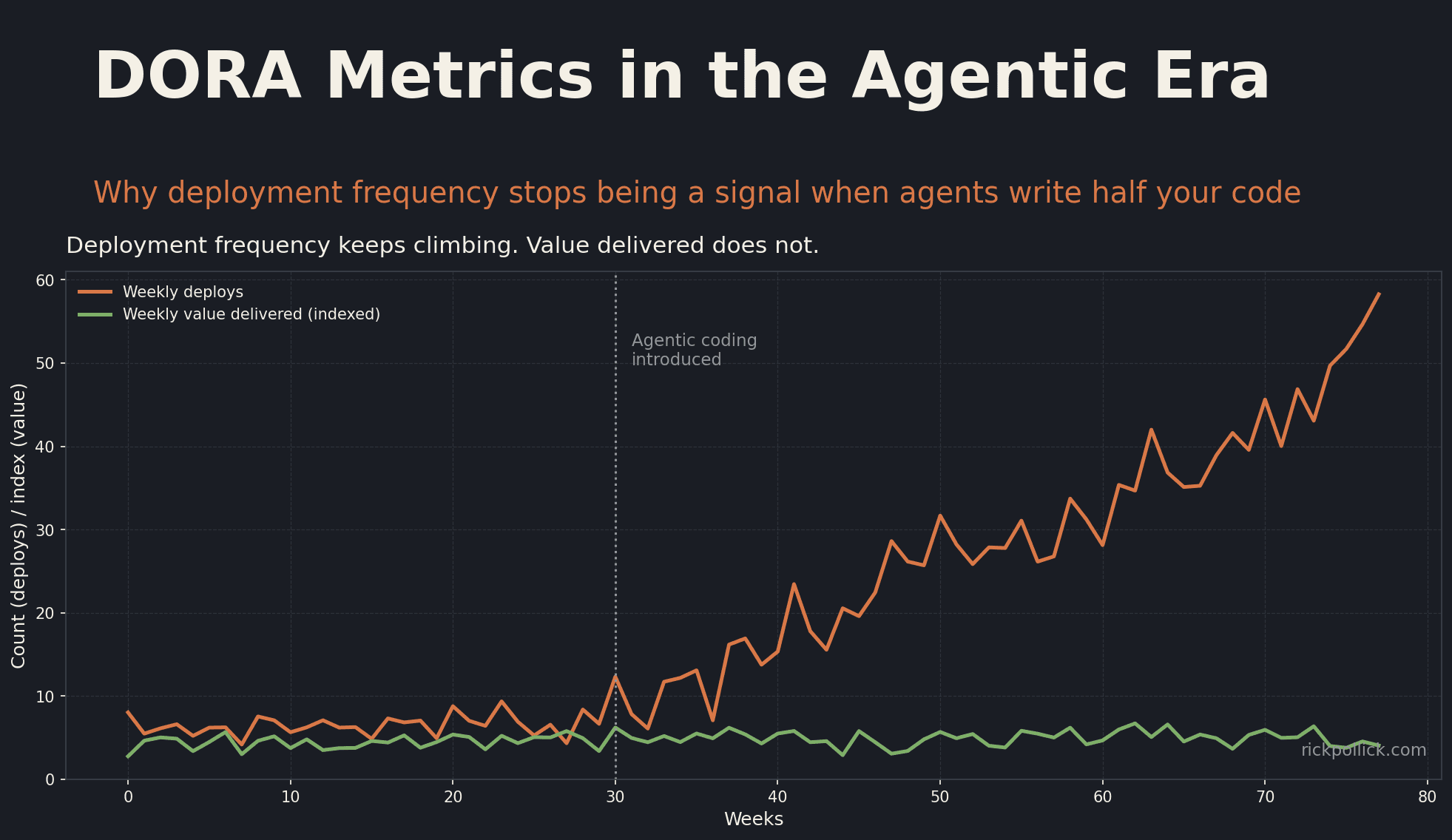
A friend of mine, the VP of Engineering at a mid-market SaaS, called last month to brag. His teams had pushed deployment frequency from 18 a week to 240 a week in one quarter. Lead time for changes was down 60 percent. On every DORA dashboard, his org had vaulted from "high" to "elite" performer overnight.
I asked him how many of those 240 weekly deploys were authored or mostly authored by agents. He paused, looked at his Jira, and said, "honestly, about 70 percent." Then I asked the question that ended the call: how much new value did customers actually see in that quarter?
He did not have a clean answer. Neither do most leaders I talk to. The DORA metrics that defined modern software delivery for a decade are quietly becoming a hall of mirrors, and the reason is that the assumptions baked into them no longer hold once AI agents are merging code to main.
The Metrics Were Built for Humans
The Accelerate research that produced DORA assumed a roughly fixed amount of human attention behind every commit, every PR, and every deploy. Deployment frequency was a proxy for throughput because each deploy cost real engineering effort. Lead time for changes measured the friction between an engineer finishing work and that work reaching customers. Change failure rate caught the cost of moving too fast. Mean time to restore measured how well your humans handled their own mistakes.
Every one of those metrics is gameable the moment you let an agent open a PR without a human authoring it. Deployment frequency goes up because the cost of producing a change collapses. Lead time falls because there is no human in the middle waiting on review. Change failure rate gets noisier in both directions: agents catch some bugs humans miss and ship others no human would have written. The whole framework drifts because the denominator, human effort, no longer correlates with the numerator, code shipped.
I am not saying DORA is dead. I am saying that anyone using the original four metrics as their primary KPI in 2026 is reading a fever chart and calling it a thermometer.
The Four Metrics, Honestly
Let me walk through how each of the original four behaves in an agentic delivery environment, and what that means for the leaders depending on them.

Deployment frequency is the most polluted of the four. Agents can open, review (with another agent), and merge dozens of dependency bumps, doc tweaks, and refactors per day. Your weekly count looks heroic. Your customers see nothing different. Worse, this metric is the easiest one to brag about in a board deck, which makes leadership susceptible to confusing motion with progress. I covered a similar trap in the end of the scrum master, where teams chased ceremony adherence instead of outcomes.
Lead time for changes suffers from a related problem. The original definition (first commit to production) shrinks toward zero when an agent generates and ships a change in the same hour. That is not necessarily good. If the change was an agent reverting another agent's earlier change, your lead time looks great while your codebase oscillates. The honest replacement is what I call outcome latency: the time from a human stating an intent to the verified delivery of that outcome in production. It is harder to measure. It is also the only number that maps back to value.
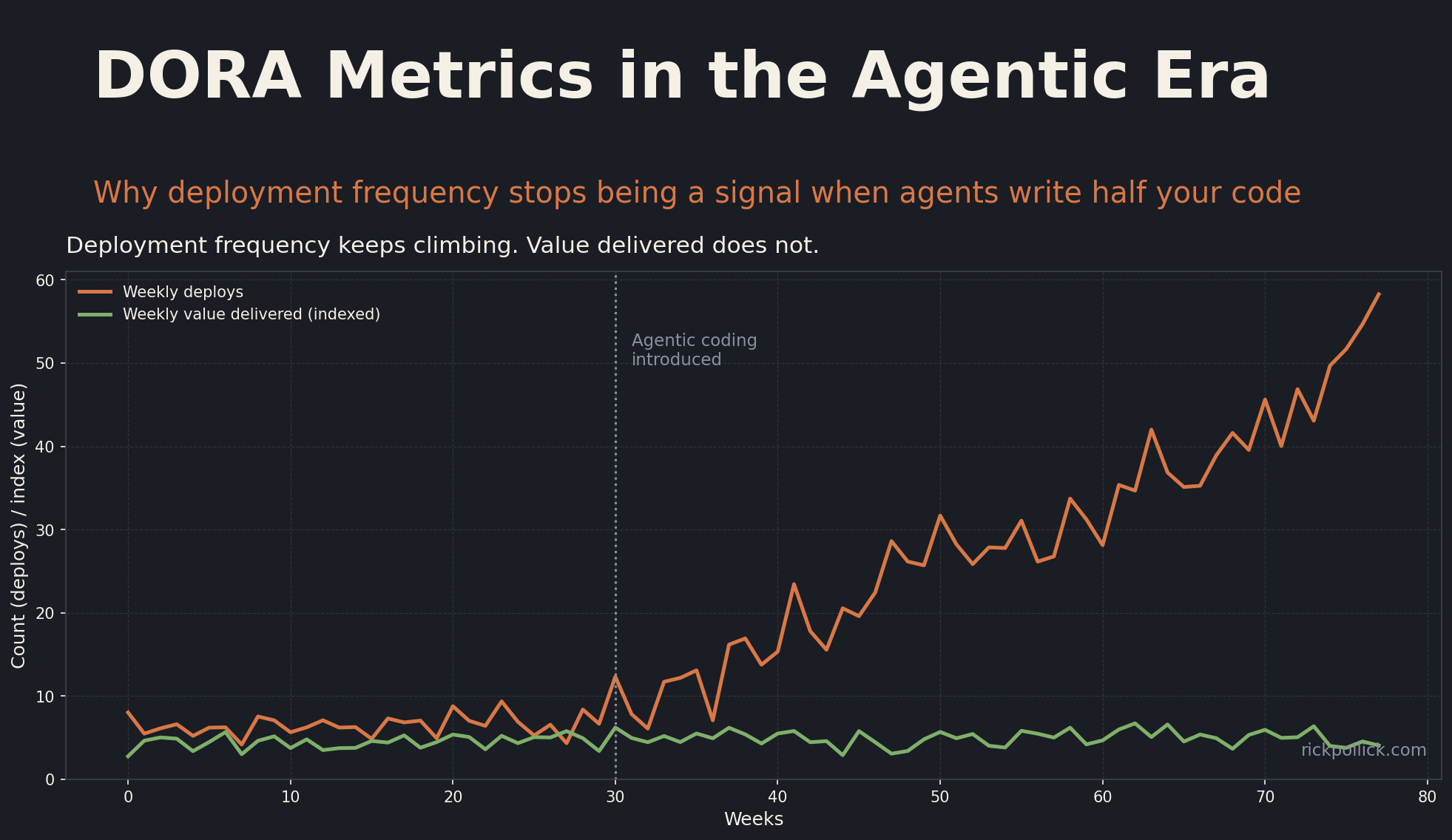
Change failure rate is the metric that should be scaring you. In every team I have worked with that turned on agentic merging without redesigning their review process, CFR has gone up, not down. Agents are great at generating plausible code. They are still mediocre at understanding the second-order effects in a real production system. The failures are often subtle: a typecast that looks right but breaks a downstream consumer, a test that passes locally but flakes under load, an API contract change that breaks a partner integration nobody on your team owns. These are the kinds of failures that increase mean time to restore.
Time to restore is the survivor. It is the one DORA metric that gets more important, not less, in an agentic world. When a third of your changes are coming from non-human authors, you are going to break things you did not predict. The teams that absorb agent-introduced incidents quickly are the ones investing in observability, runbooks, and on-call discipline. The teams that do not are losing weekends.
What Actually Broke
The reason all four metrics drifted is structural. DORA was a measurement of human throughput in a system where the bottleneck was human cognition. Agentic delivery moves the bottleneck. The new constraint is reviewer attention, not author capacity. Let me make this concrete with three patterns I see in the field.
The first pattern is PR inflation. A team turns on Copilot autonomous mode or Claude Code subagents, and the weekly PR count triples. Reviewers cannot keep up, so they either rubber stamp or ignore. Either path increases failure rate. I wrote about a related anti-pattern in vibe coding with precision; the speed gains evaporate the moment you skip the verification layer.
The second pattern is revert churn. An agent ships a change. Tests pass. A second agent (or a human) notices a regression two days later. A third commit reverts the first. By the time you average the lead times across this trio, you have a beautifully short number that hides the fact that nothing new is in production. The same closed loop happens with refactors that agents are particularly fond of: rename, rename back, slight reorganization, restore.
The third pattern is the silent CFR inflation. Agents trigger more incidents than humans, but the incidents tend to be narrower: a single endpoint, a specific tenant, a particular code path. They do not always escalate to your major incident dashboard, so your headline CFR number looks fine while a dozen small fires burn under the surface. The team that solved this for me built a tagged incident pipeline that segments incidents by author type. Their unfiltered CFR is what they report in the board deck; their agent-author CFR is what they actually manage on.
The Replacement Stack
Here is the framing I am running with my engineering clients in 2026. Keep the four original DORA metrics as compliance artifacts. Add a second layer that measures what agents make harder to see.
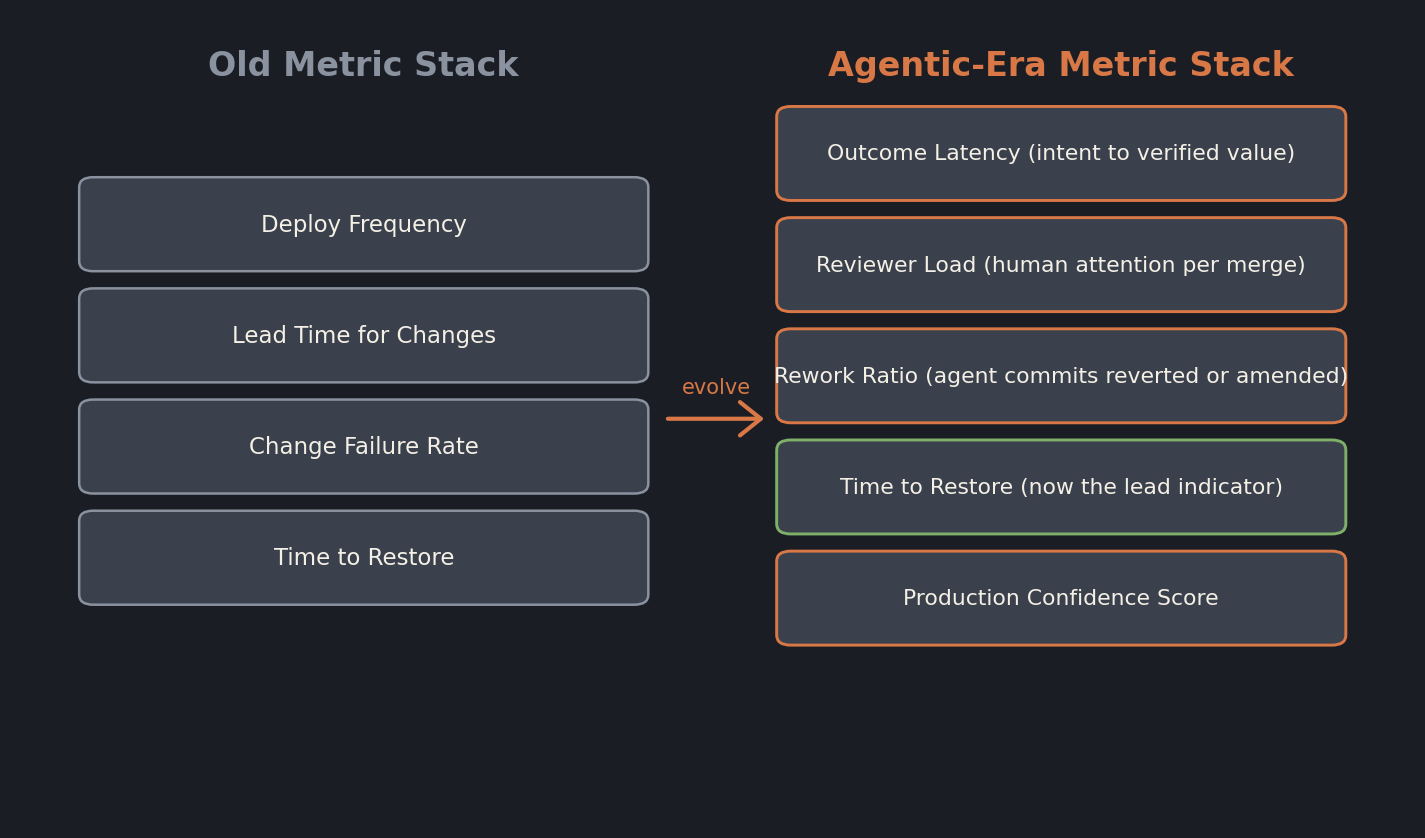
The replacement layer has five members.
Outcome latency is the time from a human-stated intent (a Jira ticket transitioning to in-progress, a product brief getting accepted, a customer commitment being made) to the verified shipment of value to a customer. This is harder to instrument than lead time, because "intent" lives in messy product systems and "verified value" requires a feature flag or analytics signal. It is also the most honest number you will track.
Reviewer load is the count of meaningful review interactions per engineer per week. If your code review minutes per engineer fall, your CFR is about to rise. The teams gaming this number with auto-approving bots discover their incident counts six weeks later. Pair this with a reviewer concentration metric: when 80 percent of merges are approved by the same two engineers, you have a reviewer scaling problem dressed up as agentic productivity.
Rework ratio is the percentage of commits in the last 30 days that revert, amend, or substantially refactor a commit also from the last 30 days. High rework ratio is the cleanest signal of the revert-churn pattern. It is also a good early indicator of agent-driven oscillation. I aim for under 10 percent on a healthy codebase.
Time to restore stays exactly where it was in the original DORA stack, but it gets promoted to your lead indicator. If MTTR creeps up, fix MTTR first and let the other metrics catch up. Investment in observability, error budgets, and incident command pays for itself faster than any other DevOps investment when agents are committing to your main branch. Worth pairing with the case I made in why platform engineering is replacing your DevOps team.
Production confidence score is a composite. I use a weighted average of test coverage on changed lines, percentage of changes behind feature flags at rollout, percentage of deployments with automated rollback configured, and percentage of deployments with explicit observability hooks added. It is intentionally coarse. Its job is to give leadership one number that captures how risky the average production change actually is, and to keep that number visible to the people approving agentic merge policies.
A Practical Migration Path
Do not try to swap your dashboards overnight. The migration that has worked for the teams I advise is three quarters long, and roughly looks like this.
In quarter one, instrument outcome latency and rework ratio alongside your existing DORA dashboard. Do not act on the new numbers yet. You are calibrating. The first month of data will be noisy. Use it to define your team's baseline.
In quarter two, add reviewer load and the production confidence score. Start segmenting your existing CFR by author type (human, agent-assisted, agent-authored). The segmented CFR is usually the moment leadership realizes the problem is real. I have watched more than one executive team change their agentic adoption posture in a single meeting after seeing the agent-authored CFR for the first time.
In quarter three, demote deployment frequency from a primary KPI to a context metric. Your headline numbers become outcome latency, segmented CFR, MTTR, and production confidence score. The four originals stay on the dashboard, but nobody is judged on them in isolation. Your governance discussions get sharper because you are arguing about value, not velocity. This is the same shift in framing I wrote about in the AI agent governance gap; the metrics evolution and the governance evolution are two sides of the same coin.
What This Means For Your Next Board Slide
If you take one thing away, take this: the DORA metrics in their original form were a contract between engineering leaders and the rest of the business. Engineering said, "these four numbers fairly represent our throughput and quality." The business trusted the numbers because there was a believable causal chain from human effort to shipped value.
That chain is broken. The numbers still look good. The chain is broken. Refusing to update the framework because the old numbers flatter you is the same mistake every previous generation of engineering leaders made when their world changed underneath them. The leaders who do the harder work of measuring outcome latency, segmented CFR, and reviewer load will be the ones whose 2027 board decks survive scrutiny.
The boring news is that the original DORA work was right about the things that matter. Throughput, stability, speed, and recovery are still the right four dimensions. The brave news is that you have to redefine the measurements for an era where the entity producing the throughput is no longer exclusively human. That is the work.
References
- Forsgren, Humble, Kim. Accelerate: The Science of Lean Software and DevOps. itrevolution.com
- Google Cloud. DORA State of DevOps Report. cloud.google.com
- Forsgren et al. The 2024 State of DevOps Report. dora.dev
- Skelton, Pais. Team Topologies. teamtopologies.com
- Beyer et al. Site Reliability Engineering. sre.google