
Evals Are the New Acceptance Criteria: Rebuilding Definition of Done for AI Features
Acceptance criteria were built for software that behaves the same way every time. AI features do not. Here is how delivery leaders rebuild Definition of Done around evals, graded thresholds, and a quality stack of evals, guardrails, and observability so probabilistic features ship with confidence.

Last quarter, a delivery lead I work with shipped an AI feature the textbook way. Every acceptance criterion was checked off. CI was green. The demo was flawless, the kind of demo that earns a round of applause in sprint review. Two weeks later, that same feature was the single largest driver of support tickets in the product.
Here is the uncomfortable part. Nothing in the process had failed. The code was reviewed. The tests passed. The acceptance criteria were met. The problem was quieter and harder to admit: the acceptance criteria were measuring the wrong kind of software. They were written for a system that does the same thing every time, and the feature underneath them did the right thing only about ninety two times out of a hundred.
This is the quiet crisis in delivery right now. Our entire definition of "done" assumes determinism, and we are shipping more and more software that is probabilistic by design. When the same input can produce a different output on Tuesday than it did on Monday, a green checkmark stops being a promise. The teams getting this right have already found the fix, and it carries a name borrowed from the machine learning world: evals. Evals are becoming the new acceptance criteria, and if you lead delivery, rebuilding your Definition of Done around them is no longer optional.
Done Was Always a Promise About Determinism
The Definition of Done is one of the most useful ideas Agile ever produced. It turned a vague feeling ("I think this is finished") into a shared, checkable contract: peer reviewed, tested, acceptance criteria met, no open critical defects. The Scrum Guide treats it as the commitment attached to the increment, the thing that makes "done" mean the same thing to the engineer, the product manager, and the customer.
Every item on a traditional Definition of Done quietly assumes the software is deterministic. "Acceptance criteria met" means you ran the scenario and got the expected result, and you can run it again tomorrow and get the same result. "Tests pass" means an assertion compared an actual value to an expected value and they matched. That assumption held for fifty years because it was true for almost everything we built.
It is no longer true for a growing slice of what your teams ship. The moment a feature routes a request through a language model, a recommendation engine, or an agent, its behavior becomes a distribution rather than a fixed value. The 2024 DORA research put hard numbers on the tension. For every twenty five percent increase in AI adoption, the report estimated a 7.2 percent drop in delivery stability and a 1.5 percent dip in throughput, even as individual productivity and job satisfaction rose. Thirty nine percent of developers said they had little or no trust in AI generated code.
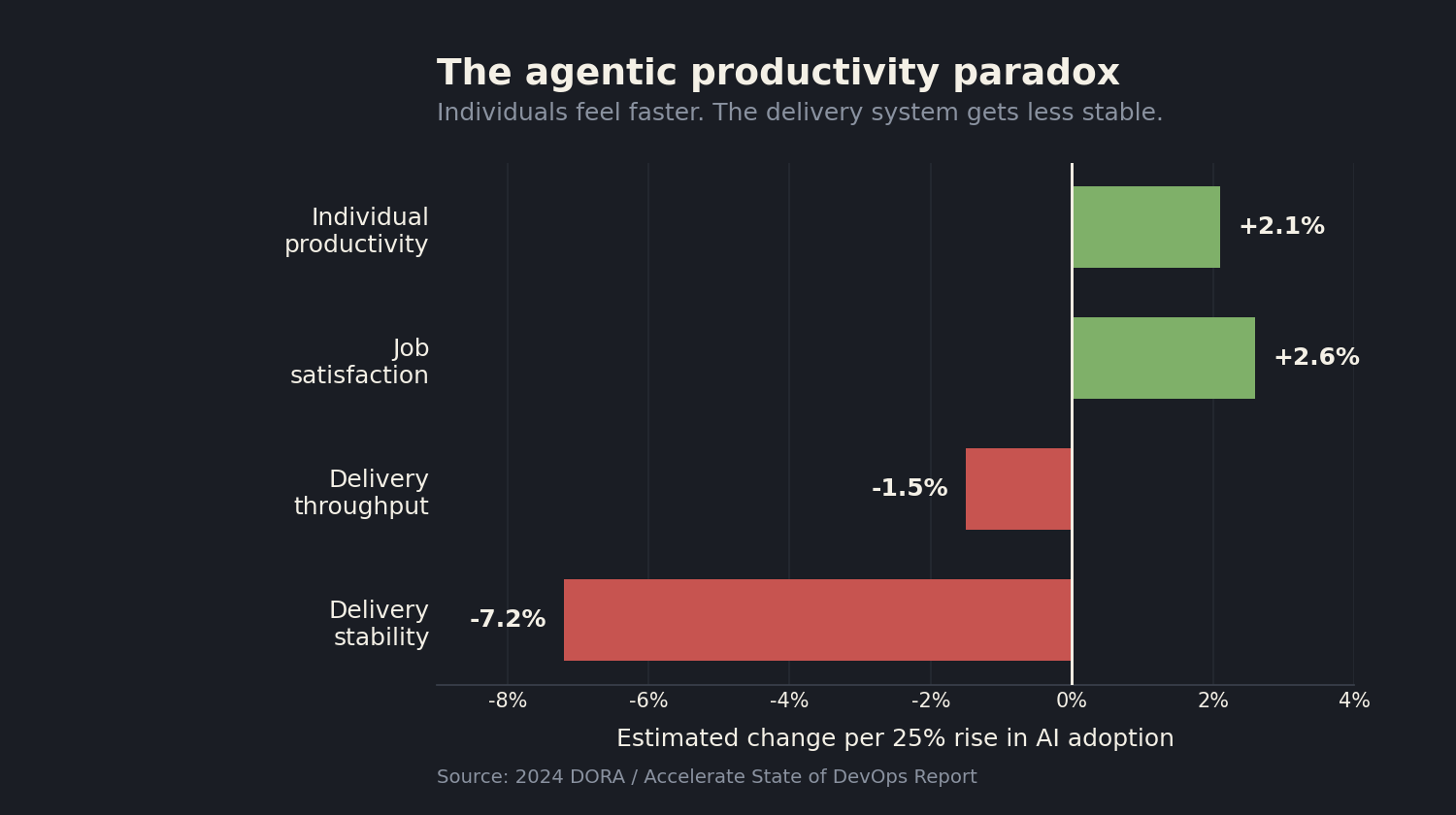
Read that chart carefully, because it is not an argument against AI. It is an argument about measurement. Individuals feel faster while the delivery system gets less stable, and the gap between those two facts is exactly the space where our old quality gates stopped working. I argued a related point in DORA metrics in the agentic era: the numbers on the dashboard still look fine while the thing they were built to represent has quietly changed underneath them. Definition of Done is the same story at the level of a single feature.
Why Pass and Fail Collapse
The cleanest way to see the break is to try to write a normal test for an AI feature.
Imagine the acceptance criterion is "when a user asks for a summary of their account, the system returns an accurate, concise summary." For deterministic software you would assert that the output equals a known string. For a language model that assertion is useless in both directions. It fails on perfectly good outputs that happen to be worded differently from your expected string, and it passes on the rare run where a wrong answer happens to match. The same prompt can produce a slightly different response on every call, because sampling is built into how these systems work.
So the unit of acceptance has to change. The question stops being "did this one run pass" and becomes "what share of representative runs clear the bar." That is the curve at the top of this post. Acceptance is no longer a checkbox; it is a threshold on a distribution. You are not asking whether the feature works. You are asking how often it works, on which kinds of input, and whether that rate is good enough to put your company's name on it.
This is not a softening of standards. If anything it is more demanding, because it forces you to state, in advance and in numbers, how good is good enough. Most teams have never had to do that. They have always been able to hide behind a binary.
What an Eval Actually Is
Strip away the machine learning vocabulary and an eval is something every delivery leader already understands: a test suite for probabilistic behavior.
It has three parts. First, a labeled dataset of representative cases, often called a golden set: real or realistic inputs paired with what a good response looks like. Second, a scoring method, which can be an exact check where the task allows it, a programmatic rule (does the output contain a valid order ID, is it under the length limit, does it parse as JSON), or, for genuinely open ended tasks, a rubric applied by a human or by another model acting as a judge. Third, a threshold: the pass rate on the golden set that a build has to reach before it is allowed to ship.
The model as judge approach is the one that feels strangest to traditional engineers, and it is worth being honest about its tradeoffs. A judge call usually costs cents rather than fractions of a cent, and it adds anywhere from a few hundred milliseconds to a few seconds of latency, so you run it in CI and on samples of production traffic, not on every keystroke. Used well, it answers the semantic questions a string comparison never could: was this summary actually faithful to the source, was this refusal appropriate, was this tone on brand. The Pragmatic Engineer guide to evals is a good practitioner walkthrough if your engineers want the mechanics.
Here is the reframing that matters for delivery. The acceptance criteria you used to write as "Given X, when Y, then Z" do not disappear. They become eval cases. Each "then" turns into a property you score, and the collection of them, with a required pass rate, becomes the executable specification for the feature. Your acceptance criteria were always trying to be evals. They just lived in a world that let them pretend to be binary.
The Three Layer Quality Stack
Evals are necessary but not sufficient, because no golden set can anticipate everything real users will type. The teams shipping probabilistic features responsibly run three layers, and each layer catches what the layer above it cannot.

Evals run pre-merge, in CI. They are your regression net. When an engineer changes a prompt, swaps a model version, or adjusts a retrieval step, the eval suite tells you whether the feature got better or quietly worse before that change reaches main. This is the layer that replaces "acceptance criteria met" on your Definition of Done.
Guardrails run at runtime. They validate inputs and outputs live, block unsafe or off policy responses, catch low confidence answers, and enforce the hard constraints that must never be violated regardless of what the model felt like generating. Evals tell you the feature is good on average; guardrails protect you from the tail.
Observability runs in production. You trace, sample, and score real traffic, because the failures that hurt most are the ones your golden set never imagined. The crucial move, the one that turns this from a diagram into a flywheel, is feeding those production failures back into the golden set so the same surprise cannot happen twice. Skip the verification layers and the speed gains evaporate, which is the trap I described in vibe coding with precision; the difference between a fast team and a reckless one is almost entirely the rigor of what happens after the model produces an answer.
Rebuilding Your Definition of Done
Put it together and your Definition of Done gains a second half. The deterministic checks do not go away, because most of any feature is still ordinary software. You add a set of graded gates for the probabilistic behavior, and you express them as thresholds you can defend with data.

The exact numbers in that image are illustrative, and that is the point: they are yours to set, per feature, per risk tier. A pass rate of ninety five percent on the golden set might be fine for a draft email assistant and nowhere near enough for anything touching money or health. A hallucination rate ceiling, a guardrail block rate, a latency budget at the ninety fifth percentile, and a rule that low confidence cases get routed to a human are all reasonable gates. What makes them powerful is that they are negotiable in the open, with evidence, instead of being hidden inside a green or red light. When product, engineering, and risk argue about whether the threshold should be ninety five or ninety eight, that argument is your governance working, not failing.
Who Owns the Eval Set
This is where the question stops being technical and becomes organizational, and where most teams get stuck.
The golden set is the executable specification for the feature, which means it cannot be owned by engineering alone. Deciding what a good answer looks like, what counts as a hallucination in your domain, and how high the bar should sit is product work and risk work. Engineering wires the eval into CI and keeps it fast; product and quality define the cases, write the rubric, and own the threshold. If your AI program treats the eval set as a testing afterthought rather than a core product artifact, you will end up optimizing for whatever was easy to measure, which is the precise failure mode I wrote about in why your agentic AI strategy will fail without product thinking.
The accountability question sits right next to it. When an agent ships a change and a probabilistic feature misbehaves in front of a customer, who answers for it? If your honest answer is "the model," you have a gap, and it is the same one I covered in the AI agent governance gap. Evals are how you close it, because a threshold someone signed off on is a decision a human made and can be held to.
What To Do Before Your Next AI Release
You do not need a platform team or a six figure tooling budget to start. You need discipline and about a sprint of patience.
Start by writing twenty to fifty golden cases. Pull them from real traffic if you have it, from expected usage if you do not, and make sure they include the ugly edge cases, not just the happy path your demo used. Pick a scoring method that fits the task, preferring programmatic checks where you can and reaching for a model as judge only where meaning genuinely matters. Set a provisional threshold and calibrate before you gate, running the eval for a sprint without blocking anything so you learn what your baseline actually is; the first week of numbers will be noisy and you should not act on them. Then wire the eval into CI and treat a threshold breach exactly like a failing test, because a Definition of Done that you can bypass under deadline pressure is not a Definition of Done. Finally, add guardrails and observability, and close the loop by routing every production failure back into the golden set.
The Honest Part
A green test suite was always a contract between engineering and the rest of the business. It said, in effect, "we checked, and this does what we agreed it would do." For deterministic software that contract was believable, because the behavior you verified on Monday was the behavior your customer got on Friday.
For probabilistic software that contract is void unless you rewrite what "pass" means. The feature my colleague shipped last quarter was not a process failure. It was a definitional one. The team did everything their Definition of Done asked, and their Definition of Done was asking the wrong questions. The teams that rebuild it around evals, graded thresholds, and a quality stack that learns from production will ship AI features their customers actually trust. The teams that keep treating a probabilistic system like a deterministic one will keep shipping demos that earn applause in the sprint review and generate support tickets by the end of the month. The choice is which kind of "done" you are willing to put your name on.
References
- DORA. Accelerate State of DevOps Report 2024. dora.dev
- Schwaber, Sutherland. The Scrum Guide. scrumguides.org
- Pragmatic Engineer. A Pragmatic Guide to LLM Evals. newsletter.pragmaticengineer.com
- Lu, Xing, et al. Evaluation-Driven Development and Operations of LLM Agents. arxiv.org