
From Gantt to Graph: Why Modern Project Management Demands Technical Fluency
Modern project management is bilingual. Read an architecture decision record, reason about an error budget, and trace a CI dependency, or get pattern matched to the steering committee. A practitioner's guide to the five technical artifacts every PM should know, the dependency-graph critical path, technical risk frameworks, and the trust contract that earns engineering's respect.

If your project management toolkit still starts with a Gantt chart and ends with a status report, you are managing a 1995 program with 2026 stakes.
PMI's most recent Pulse of the Profession data is uncomfortable: a minority of projects finish on time, on scope, and on budget. The numbers get worse for technology programs. The McKinsey and Oxford joint study on large IT projects reported that, on average, they run 45 percent over budget, 7 percent over time, and deliver 56 percent less value than predicted. When you talk to the program leads who shipped the failures, you almost never hear "we had bad estimates." You hear "we did not see the dependency until it bit us," or "the architecture changed three times and we never rebaselined the plan," or "engineering told us, we just did not understand."
This is not a critique of project managers. It is a critique of how we still train them. The discipline is mid transformation. The PM who can read an architecture decision record, trace a deployment pipeline, and reason about an error budget is now the PM who delivers. Everyone else is a secretary for the steering committee.
Here is what the next generation of project leadership looks like, and what to do this quarter to get there.
1. From schedule manager to system steward
The classic PM job description: scope, time, cost, quality, risk, communication, stakeholder management. None of that goes away. What changes is what each of those nouns refers to in a modern program.
Scope is no longer a list of features. It is a graph of services, contracts, data flows, and SLOs. Time is no longer a Gantt bar. It is a release train with branching strategies, feature flags, and progressive rollout windows. Risk is no longer "vendor delivery slip." It is a cluster of architectural, operational, security, data, and capability risks, most of which only an engineering lead can articulate without help.
The modern technical PM does not replace the engineering manager. The PM is the connective tissue that lets the architecture, the delivery plan, the risk register, and the executive narrative stay coherent as the system mutates underneath them. That requires reading the system, not just reporting on it.
2. The five technical artifacts every PM should be able to read
You do not need to write code. You do need to read these five things without translation.

First, Architecture Decision Records. ADRs capture why a team chose Postgres over DynamoDB, or REST over gRPC, or a monolith over microservices. The ADR is the program's institutional memory. If your project has a major dependency on a system, you should have read its key ADRs. When the executive asks "why can we not just swap the database," the answer is in the ADR, not in your head.
Second, dependency graphs and service topology maps. Most large programs have at least one diagram, often outdated, that shows which service calls which. Get it. Update it. Reference it in every steering committee. The longest path through that graph is your real critical path, and it is rarely the same as the one in your project plan.
Third, SLO and SLA documents with error budgets. If a downstream service has a 99.9 percent SLO and you are about to ship a change that consumes the next two months of error budget in a single release, you do not have a delivery plan, you have a self-inflicted incident. Error budgets are a forecasting tool. PMs who treat them that way avoid 2 a.m. rollback calls. The Google SRE workbook is the cleanest treatment of this material if you are starting from zero. I have written more on the related topic of why platform engineering is replacing your DevOps team if you want to see how the operating model is shifting.
Fourth, release pipelines and deployment topologies. Where does the artifact get built, where is it scanned, where is it staged, who can promote it, what gates exist, who owns each gate. A modern project plan that does not encode the pipeline is a fiction.
Fifth, data flow diagrams. Especially in regulated environments, the question "what data crosses what boundary, governed by what control" is half the program. Privacy, residency, lineage, retention. Your delivery plan needs to reflect every one of those gates.
3. The new critical path is a dependency graph
The traditional critical path looks like a chain of tasks: A blocks B blocks C. The modern critical path is a directed acyclic graph that includes things the old method ignored.
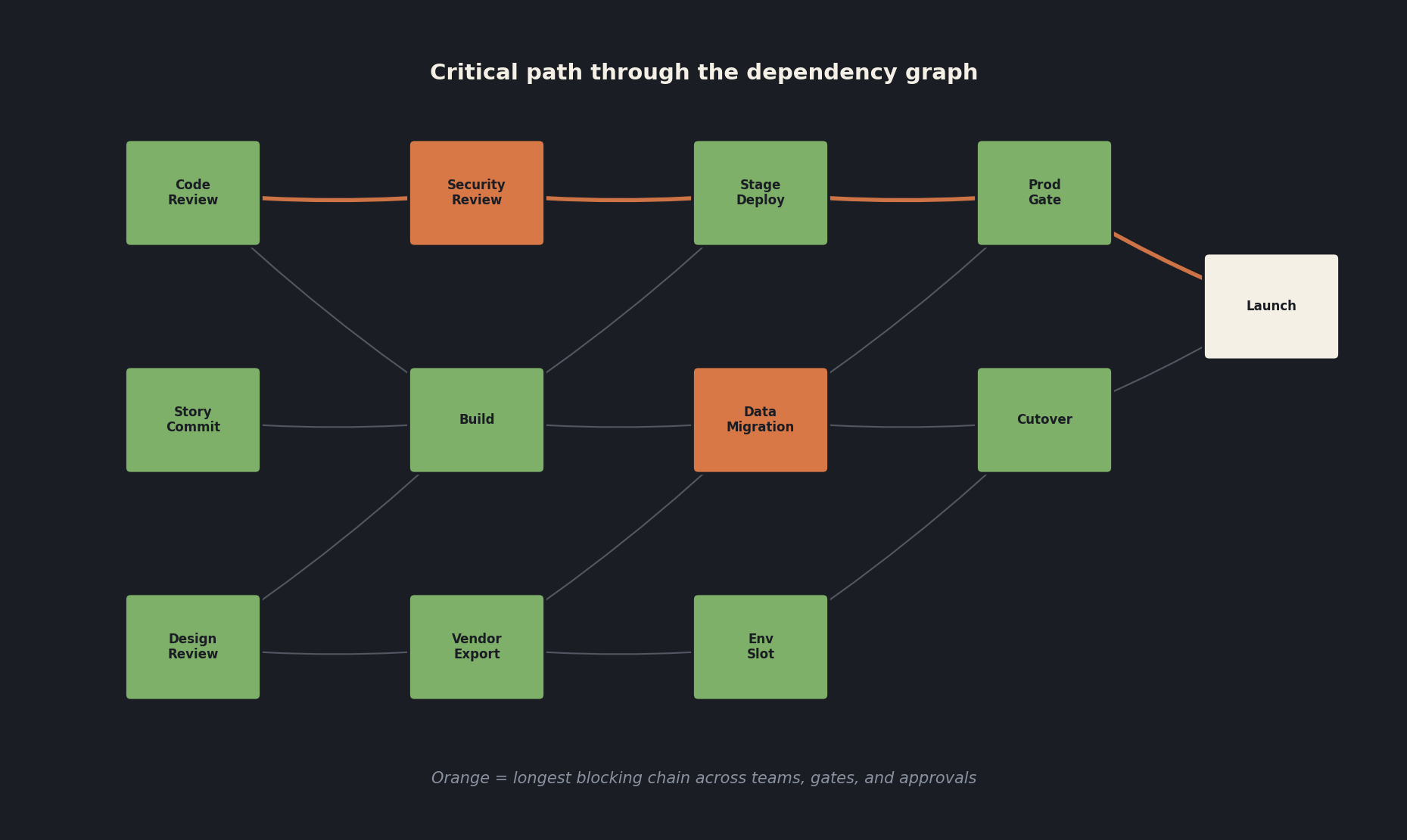
Try this exercise. Take any milestone on your current plan that is at risk. Walk back from it and write down everything that has to be true for it to land. You will list tasks. Keep going. Soon you will list a code review SLA that has been breached for 9 days, an environment that is shared with another program that has priority, a security review that is queued behind 14 other tickets, a data migration that depends on a vendor's export window, and an unmerged pull request whose owner is on parental leave. None of those are tasks in the conventional sense. All of them are on your critical path.
This is also the same insight that drove an earlier post on dependency latency, decision aging, and acceptance criteria entropy as leading indicators of project failure. The instrumentation in that post pairs naturally with the graph view here.
Modern PM tools make this easier. Linear, Jira Advanced Roadmaps, Smartsheet, and the newer entrants like Productboard and ClickUp now expose dependency views that pull from issue trackers, GitHub, and CI/CD systems. Use them. The PM whose dependency graph is one click from the source of truth wins. The PM who copy-pastes from a Jira dashboard into a slide every Thursday is shipping vibes.
4. Risk management gets technical, owners get specific
A risk register that says "Risk: integration may slip. Mitigation: monitor weekly. Owner: Engineering" is a mitigation plan in name only.
A technical risk register names the risk in engineering terms, names the asset, names the owner with technical authority, and names the trigger.
Example, weak: "Database performance risk."
Example, strong: "Risk: query latency on the orders read replica exceeds 200 ms p95 under projected Black Friday load. Owner: Sarah, Staff Engineer, Orders. Mitigation: index plan in ADR 0042, load test by week of 11 Sep, fall back is read scaling group. Trigger to escalate: any p95 above 250 ms in load test."
That is a risk a PM can manage with a calendar and a clear escalation. The first version is a worry, not a risk.
The shift here is small but profound. PMs who can frame risks in operational and architectural terms get treated as peers by engineering. PMs who cannot, get pattern matched to the steering committee, and engineers route around them.
5. The trust contract with engineering
Engineering teams have a long memory for two PM behaviors. The first is asking "when will it be done" once a week and never asking "what would help." The second is treating "we do not know yet" as a project management failure rather than as truthful information.
Replace both with two questions and a habit.
Question one: what is the smallest thing we can ship that would prove or kill the riskiest assumption. This is product thinking applied to delivery. If the answer is "a working ingestion pipeline that processes 100 MB of real data," that is your next milestone, not the full feature.
Question two: what would have to be true for this to slip a quarter, and what is the leading indicator we would see first. This forces the team to name early warning signs, which is the entire point of risk management.
The habit: ask for the rollback plan, the runbook, and the architecture diagram before you write the project plan, not after. If those three artifacts do not exist, that is your first finding, and it will save the program more time than any standup.
6. The technical PM's reading list
The PMBOK Guide is not wrong. It is necessary and not sufficient. Augment it with material that teaches you to think about systems.
For systems thinking and engineering culture: Accelerate by Forsgren, Humble, and Kim is the foundational text on what high-performing software organizations measure and why. Team Topologies by Skelton and Pais reshapes how you think about team boundaries and dependency cost. The Google SRE Workbook is the cleanest free treatment of error budgets and SLOs available.
For modern delivery practice: the DORA State of DevOps Report, published annually, gives you the four key metrics, deployment frequency, lead time for changes, change failure rate, and mean time to recovery, that should appear on every steering deck for a software program. If your delivery dashboard does not include these, you are reporting on the wrong things.
For architecture literacy: Fundamentals of Software Architecture by Richards and Ford is approachable for non-engineers. Read it once, skim it forever.
And the one thing none of those books will give you: spend two weeks shadowing an engineering lead. Sit in the architecture review. Sit in the incident postmortem. Sit in the on-call rotation handover. You will learn more about your own program in those two weeks than in two quarters of status meetings.
Conclusion
Project management is not dying. It is being upgraded. The new bar is bilingual. You should still know how to run a steering committee, build a budget, and write a charter. You should also be able to read an ADR, reason about an error budget, and trace a dependency through a CI pipeline.
The PMs who do this are the ones whose programs ship. The PMs who do not are managing the appearance of progress while engineering ships around them.
Pick one technical artifact this quarter. Read every version of it on your program. Write a one-page summary of what it implies for your plan. Bring that to your next steering meeting instead of the schedule slip slide. You will be surprised how quickly you become indispensable.
References
- PMI. Pulse of the Profession 2024. pmi.org
- McKinsey and University of Oxford. Delivering large-scale IT projects on time, on budget, and on value. mckinsey.com
- Forsgren, Humble, and Kim. Accelerate. IT Revolution Press
- Skelton and Pais. Team Topologies. teamtopologies.com
- Google. Site Reliability Engineering Workbook. sre.google
- DORA. State of DevOps Research. dora.dev
- Richards and Ford. Fundamentals of Software Architecture. O'Reilly